



Microsoft continues so as to add to the dialog by unveiling its latest fashions, Phi-4-reasoning, Phi-4-reasoning-plus, and Phi-4-mini-reasoning.
A brand new period of AI
One yr in the past, Microsoft launched small language fashions (SLMs) to clients with the discharge of Phi-3 on Azure AI Foundry, leveraging analysis on SLMs to develop the vary of environment friendly AI fashions and instruments out there to clients.
At the moment, we’re excited to introduce Phi-4-reasoning, Phi-4-reasoning-plus, and Phi-4-mini-reasoning—marking a brand new period for small language fashions and as soon as once more redefining what is feasible with small and environment friendly AI.
Reasoning fashions, the subsequent step ahead
Reasoning fashions are educated to leverage inference-time scaling to carry out advanced duties that demand multi-step decomposition and inside reflection. They excel in mathematical reasoning and are rising because the spine of agentic purposes with advanced, multi-faceted duties. Such capabilities are usually discovered solely in giant frontier fashions. Phi-reasoning fashions introduce a brand new class of small language fashions. Utilizing distillation, reinforcement studying, and high-quality information, these fashions stability measurement and efficiency. They’re sufficiently small for low-latency environments but keep sturdy reasoning capabilities that rival a lot greater fashions. This mix permits even resource-limited units to carry out advanced reasoning duties effectively.
Phi-4-reasoning and Phi-4-reasoning-plus
Phi-4-reasoning is a 14-billion parameter open-weight reasoning mannequin that rivals a lot bigger fashions on advanced reasoning duties. Educated by way of supervised fine-tuning of Phi-4 on rigorously curated reasoning demonstrations from OpenAI o3-mini, Phi-4-reasoning generates detailed reasoning chains that successfully leverage extra inference-time compute. The mannequin demonstrates that meticulous information curation and high-quality artificial datasets permit smaller fashions to compete with bigger counterparts.
Phi-4-reasoning-plus builds upon Phi-4-reasoning capabilities, additional educated with reinforcement studying to make the most of extra inference-time compute, utilizing 1.5x extra tokens than Phi-4-reasoning, to ship increased accuracy.
Regardless of their considerably smaller measurement, each fashions obtain higher efficiency than OpenAI o1-mini and DeepSeek-R1-Distill-Llama-70B at most benchmarks, together with mathematical reasoning and Ph.D. stage science questions. They obtain efficiency higher than the total DeepSeek-R1 mannequin (with 671-billion parameters) on the AIME 2025 check, the 2025 qualifier for the USA Math Olympiad. Each fashions can be found on Azure AI Foundry and HuggingFace, right here and right here.
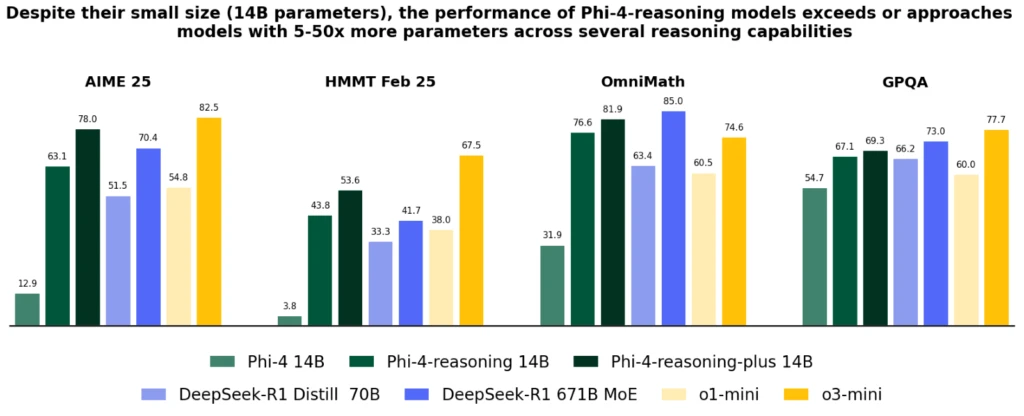

Phi-4-reasoning fashions introduce a significant enchancment over Phi-4, surpass bigger fashions like DeepSeek-R1-Distill-70B and method Deep-Search-R1 throughout varied reasoning and common capabilities, together with math, coding, algorithmic downside fixing, and planning. The technical report supplies intensive quantitative proof of those enhancements by means of various reasoning duties.
Phi-4-mini-reasoning
Phi-4-mini-reasoning is designed to fulfill the demand for a compact reasoning mannequin. This transformer-based language mannequin is optimized for mathematical reasoning, offering high-quality, step-by-step downside fixing in environments with constrained computing or latency. Wonderful-tuned with artificial information generated by Deepseek-R1 mannequin, Phi-4-mini-reasoning balances effectivity with superior reasoning means. It’s splendid for instructional purposes, embedded tutoring, and light-weight deployment on edge or cellular methods, and is educated on over a million various math issues spanning a number of ranges of problem from center college to Ph.D. stage. Check out the mannequin on Azure AI Foundry or HuggingFace at the moment.
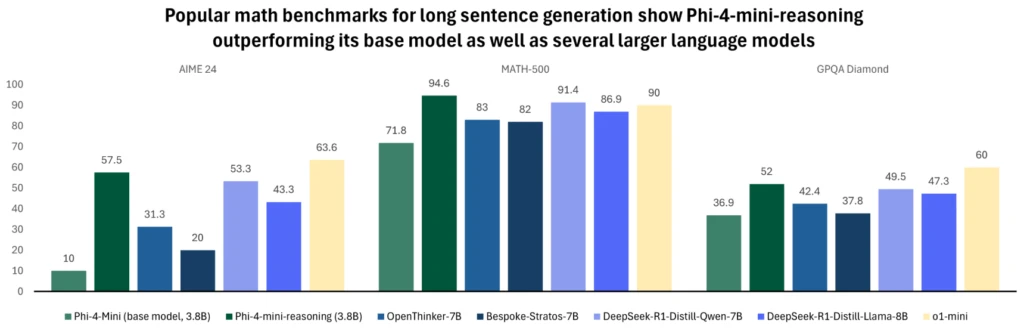
For extra details about the mannequin, learn the technical report that gives extra quantitative insights.
Phi’s evolution over the past yr has regularly pushed this envelope of high quality vs. measurement, increasing the household with new options to deal with various wants. Throughout the dimensions of Home windows 11 units, these fashions can be found to run regionally on CPUs and GPUs.
As Home windows works in the direction of creating a brand new kind of PC, Phi fashions have grow to be an integral a part of Copilot+ PCs with the NPU-optimized Phi Silica variant. This extremely environment friendly and OS-managed model of Phi is designed to be preloaded in reminiscence, and out there with blazing quick time to first token responses, and energy environment friendly token throughput so it may be concurrently invoked with different purposes working in your PC.
It’s utilized in core experiences like Click on to Do, offering helpful textual content intelligence instruments for any content material in your display, and is accessible as developer APIs to be readily built-in into purposes—already being utilized in a number of productiveness purposes like Outlook, providing its Copilot abstract options offline. These small however mighty fashions have already been optimized and built-in for use throughout a number of purposes throughout the breadth of our PC ecosystem. The Phi-4-reasoning and Phi-4-mini-reasoning fashions leverage the low-bit optimizations for Phi Silica and can be out there to run quickly on Copilot+ PC NPUs.
Security and Microsoft’s method to accountable AI
At Microsoft, accountable AI is a elementary precept guiding the event and deployment of AI methods, together with our Phi fashions. Phi fashions are developed in accordance with Microsoft AI ideas: accountability, transparency, equity, reliability and security, privateness and safety, and inclusiveness.
The Phi household of fashions has adopted a strong security post-training method, leveraging a mixture of Supervised Wonderful-Tuning (SFT), Direct Choice Optimization (DPO), and Reinforcement Studying from Human Suggestions (RLHF) strategies. These strategies make the most of varied datasets, together with publicly out there datasets centered on helpfulness and harmlessness, in addition to varied safety-related questions and solutions. Whereas the Phi household of fashions is designed to carry out a variety of duties successfully, it is very important acknowledge that every one AI fashions could exhibit limitations. To raised perceive these limitations and the measures in place to deal with them, please discuss with the mannequin playing cards under, which give detailed info on accountable AI practices and tips.
Study extra right here:

{kind=link}